General Practice Extraction Service (GPES) Data for Pandemic Planning and Research (GDPPR): a guide for analysts and users of the data
This guidance provides an overview of the dataset for analysts and other users of the GDPPR which provides information for COVID-19 planning and research.
It provides an overview of the dataset for analysts and other users of the GDPPR that provides information for COVID-19 planning and research. The following information is provided:
An overview of the generic GPES data extraction mechanism.
A description of the specific extract requirement used to provide the GDPPR extract:
- frequency of extraction
- participation of GP practice participation
- data model
- fields extracted and their types
- patient inclusion or exclusion criteria
- the coded information extracted from each patient record (if present) in the form of code clusters
- data coverage management information
It is intended for consumption by a wide group of stakeholder groups: clinicians, patients, Information Governance (IG) professionals and anyone with a need to understand how the extract operates and what data is being extracted for the purposes of COVID-19 planning and research.
It does not replace the technical specification (extraction requirement) that GP system suppliers (GPSS) will utilise to build the extract.
The legal basis for NHS England to collect and analyse GDPPR is not covered in detail within this guidance. See the Data Provision Notice for further information on this. NHS England has also undertaken a Data Privacy Impact Assessment and published a Transparency Notice in accordance with its obligations under the UK General Data Protection Regulation (UK GDPR).
Background
The COVID-19 pandemic led to urgent demand for general practice data for planning and research.
NHS Digital (now NHS England) was requested by the joint co-chairs of the Joint GP IT Committee (JGPITC), which comprises membership from the British Medical Association (BMA) and the Royal College of General Practitioners (RCGP), to provide a tactical solution during the period of the COVID-19 pandemic to meet this demand and to relieve the growing burden and responsibility on general practices.
On 15 April 2020 the BMA and RCGP therefore gave their support via JGPITC to NHS Digital’s proposal to use the GPES to deliver a data collection from general practices, at scale and at pace, as a tactical solution to support the COVID-19 response in the pandemic emergency period.
The legal basis for NHS England to establish and operate an information system for the collection and analysis of the data is the COVID-19 Public Health Directions 2020. The extract will be used to:
- respond to and manage the increased demand for data for COVID-19 planning and research
- make sure data is stored securely and disseminated appropriately and safely using our robust Data Access Request Service (DARS), with independent oversight provided by the Advisory Group for Data (AGD) and the Patient Advisory Group (PAG)
- reduce burden on GP practices and allow GPs to focus on patient care
Summary of the end to end process
1. While the data sits within the GP system supplier (GPSS) boundary the GP practice is the data controller
NHS England’s legal basis to establish and operate an information system to collect and analyse GDPPR is the COVID-19 Public Health Directions 2020. NHS England requires the data from practices in accordance with its powers under s259(1)(a) of the Health and Social Care Act 2012. This requirement is notified to practices through the Data Provision Notice.
The data set was developed with stakeholders based on pandemic need at the time of development. Practices are provided with consistent and exemplary fair processing information for the data collected by NHS England.
Data is only taken from the practice where a practice has accepted the offer to participate in the service via the Calculating Quality Reporting Service (CQRS). Not all patients are included in the extract. Only specific coded and structured data will be extracted by the GPES and sent to NHS England.
The patient data is transferred from the GPSS to the NHS England Data Processing Service (DPS) using the Message Exchange for Social Care and Health (MESH) service for secure large file transfers.
2. Upon data landing, NHS England and the Department of Health and Social Care (DHSC) become joint data controllers
Data is passed through a secure ‘data pipeline’ where it is ingested, validated and has derivations applied before being stored separately to other data assets.
Upon landing the DPS takes the extract file from the landing zone file store and applies validation and data quality (DQ) checks. The DPS then calls the De-Identification Service to tokenise identifiers to the DPS internal pseudonyms ahead of storage.
3. Processed data is then held securely in an encrypted and pseudonymised form, in isolation from other data sets and NHS England staff
All data held is protected by system level security policies. Data sets are stored as objects in AWS S3 Buckets with controlled access via Identity and Access Management (IAM) mechanisms. Files are not publicly readable and data is encrypted at rest in S3 using AES-256.
4. Applications to request data must include a clear purpose(s) and evidence a legal basis to access the data. Applications will be assessed against internal DARS standards and independent, external AGD and PAG advice will be sought where appropriate
This is to ensure:
- the data file only contains data that has been authorised for dissemination under a data sharing agreement (DSA) approved through DARS
- the file will be sent to the recipient using a secure mechanism such as MESH
- each recipient will receive data with a different set of pseudonyms (based on the DSA)
NHS England will consult with the BMA and RCGP on all requests for access to this data which are received by DARS. An outline of the process that has been agreed with the BMA and the RCGP is published on the NHS England website.
5. Upon approving the application, data can be linked and/or re-identified ahead of dissemination where required
Upon being granted approval the data can be linked to other data sets. Any further processing including linkage is only undertaken following DARS approval. Data does not need to be re-identified to be linked to other data sets. Where re-identification is approved to meet a specific purpose it is strictly controlled, monitored and fully auditable. Multiple steps and security levels are required to execute.
6. NHS England’s responsibility for the data does not stop at the dissemination and audit. Sanctions are imposed for any organisation deemed to have breached the DSA
These include:
- revocation of the DSA and access to the data
- data destruction notice
- customer being reported to the Information Commissioner’s Office (ICO) for data breaches.
Once all approvals have been obtained and the data prepared it can then be accessed by the requesting organisation within the Data Access Environment (DAE). DAE is a single access environment for NHS England and external users to access this data. DAE supports a number of presentation tools. By default, users cannot download the results of queries from DAE. However, there are cases, typically involving cohort management, where this is necessary, in which case the user is granted specific permission to download the data.
GPES extraction overview
The GPES is a generic data extraction service operating between NHS England and GP system suppliers that allows NHS England to query GP systems for data in the form of specific data extractions (an extraction requirement) to meet the needs of a particular data use case. Examples of existing data extractions are those that provide the basis for GP payments or those that are used for health screening. The GPES extracts and benefits provides further information on the data collections extracted via GPES and the purposes associated with each.
The GPES provides standard mechanisms for controlling and scheduling extractions as well as targeting and controlling practice involvement (Participation). This allows control of the population (Cohort) for which data is extracted as well as, where applicable, GP data control of whether the extraction is authorised to take place.
This GDPPR extract is an extract which has been developed by GPSS and is undertaken by NHS England to extract the relevant data for central processing.
The actual subset of available data that is extracted in each GPES extract is defined by a set of business rules. These rules specify features such as the target cohort of patients, the patients qualifying for extraction, the coded record content for extraction and limitations such as time period cut-offs to be applied to the extracted content.
The following sections provide an overview of the business rules that specify the actual subset of patient data held by GP systems that will be included in the GDPPR extract.
Extract frequency
GDPPR was an initial extract, followed by a fortnightly extraction. From March 2024, it changed to a monthly extraction. Data is up-to-date as of the day before each extract takes place. The data will be made available for dissemination approximately one week after the latest extraction date. The data available for dissemination will be between 2 and 6 weeks old.
The initial GDPPR extract consisted of patient demographic information and coded medical information (as per the business rules) as a snapshot in time when the first extract was undertaken. A snapshot in this context means data recorded up to the date the extract was taken, looking back through the full history of the relevant parts of the patient record stored within their GP system. Thereafter subsequent fortnightly, and now monthly, extracts have been undertaken. The monthly extracts ask for the same data items (patient demographics and coded medical information) and snapshot as defined in the initial extract but from a more specific group of patients, namely any who meet at least one of the criteria below. This group of patients are described as below:
1. Patients who have recently registered at a GP practice in the month up to and including the reporting period end date.
2. Patients who have any codes relevant to pandemic planning and research recorded in the month up to and including the reporting period end date
3. Patients who have any codes relevant to pandemic planning and research and whose date of death is in the month up to and including the reporting period end date.
Please note - GDPPR changed to a monthly extract from March 2024.
- patients register at a new practice
- journals are added
- journals are added and removed in between reporting periods
- patients have died
- only changes made in the patient section of the record
- only journals are removed
- only contents of journals are changed
- patients are deleted from practice registers
- patients registered at a new practice one month before the reporting period end date until they have any relevant codes recorded within their new practice
Practice participation
As data controllers of data in their GP systems, general practices are required to opt-in to this extraction by accepting the offer to participate in the service on CQRS. Data will not be extracted by GPSS for any practices that have not opted-in via CQRS.
Patient inclusion or exclusion
Candidate patient records for extraction are patients with active, current registrations at participating practices and deceased patients with a date of death on or after 1 November 2019.
Records will not be extracted from patient records with a recorded dissent from secondary use of GP patient identifiable data, thereby respecting the Type 1 data opt-out. Further information is published on the care information choices webpage.
Patient records will be included where they have coded record content that matches the codes defined by the Code Clusters applicable for the GDPPR extract.
General content exclusions
The extract does not include any free-text notes or documents attached to patient records.
Extract scope and content
The GPES-I standard models patient data held in GP systems via four main entities in what is commonly referred to as the 4 table model.
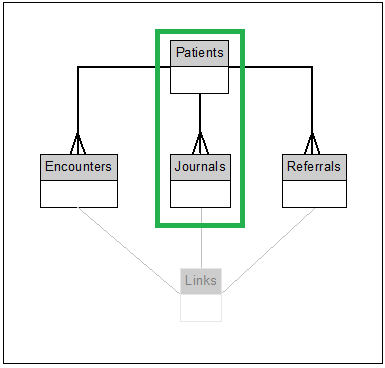
The entities in scope for the GDPPR extraction are patients and journals only.
Data flow
The data from GPSS flows through an ingestion pipeline through the NHS England DPS platform which operates on AWS using Simple Storage Service (AWS S3). See the diagram below for further information:

Code clusters and content
The rules and logic governing patient inclusion and extracted record content is provided by the GPES Extract for pandemic planning and research_business_rules_v2.0 or later version. For the latest content of the code clusters see below.
The business rules document defines the set of code clusters setting out the inclusion criteria for coded record content in terms of SNOMED CT reference sets. The contents of each refset are available via Technology Reference data Update Distribution (TRUD)or Power BI portal. An example of a subset of the defined refsets is shown in this table.
| Cluster name | Description | SNOMED CT |
|---|---|---|
| AAA_COD | Abdominal aortic aneurysm diagnosis codes | ^999016371000230105 |
| ABPM_COD | Ambulatory blood pressure codes | ^999016411000230109 |
| ACE_COD | Angiotensin-converting enzyme (ACE) inhibitor prescription codes | ^12464201000001109 |
Where applicable, time-based cut offs are applied to extracted journal entries for example within 2 years of the extraction date. These time-based cut-offs are also defined in the business rules document.
This table is an example of a 2-year cut-off being applied to codes belonging to the ambulatory blood pressure code cluster. Where no time-based cut of is applied all instances of a qualifying code are extracted.
| Field number | Field name | Code cluster (if applicable) | Qualifying criteria | Returned fields | Non-technical decision |
|---|---|---|---|---|---|
| 1 | {ABPM_DAT} | ABPM_COD |
All > (RPED - 2 years) AND <= RPED |
Refer to 4.4 Patient-level Extracts |
The specified fields for all ambulatory blood pressure codes recorded in the 2 years up to and including the reporting period end date. |
To give context to the code clusters used in this dataset
- there are over 900,000 SNOMED codes in the UK and international releases including drug codes and inactive codes
- there are over 34,000 SNOMED codes used within the GDPPR dataset (all current NHS England GP extracts cover 36,400 SNOMED codes)
Similar SNOMED codes are grouped together into code clusters. For example, there are 18 SNOMED codes which refer to a patient receiving a seasonal influenza vaccine; these 18 SNOMED codes are grouped under the code cluster ‘Flu vaccination codes’. The same occurs with the 17 SNOMED codes which denote a patient receiving an MMR vaccine to produce the ‘MMR vaccine codes’ code cluster. These two code clusters are then grouped together under a wider cluster category, ‘Vaccines and immunisations’, along with several other relevant code clusters. The document or Power BI report below can be used to understand the hierarchical structure of SNOMED codes, code clusters and categories, and can help users decide which may be relevant to their research.
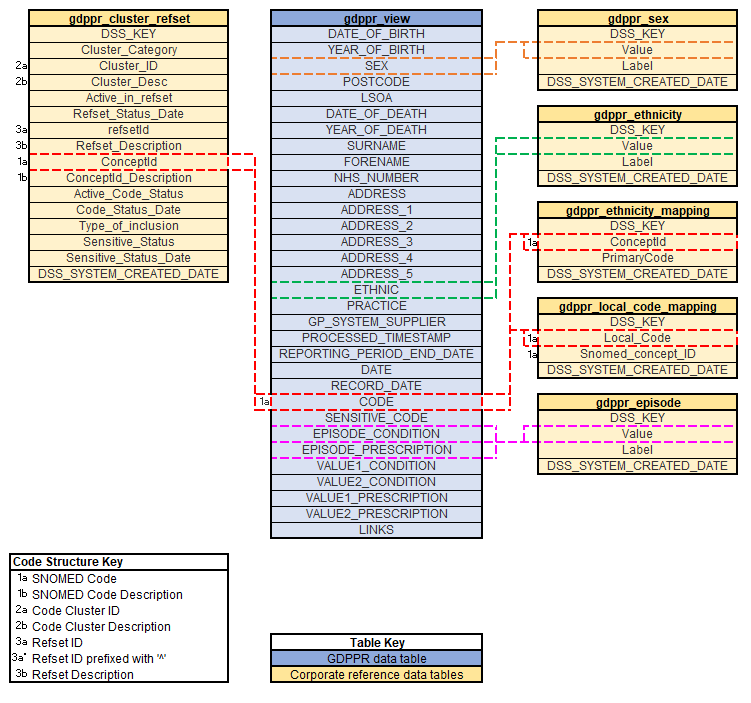
Only the individual SNOMED code is included within each journal record. Therefore, in order to filter the data using specific code clusters or refsets the provided reference data must be utilised. For Data Access Environment (DAE) users, reference data is available in the dss_corporate database. Care must be taken when joining GDPPR data to reference data as SNOMED codes can appear in more than one code cluster
This diagram shows which fields in the reference data can be used to link to the GDPPR data.
Utilisation views
For efficiency, the two logical tables, JOURNALS and PATIENTS, extracted via the GPES extract are merged into a single combined table for utilisation as a data set by NHS England. This does not alter the data extracted or compromise security or information governance of the received data. It means that both the records that describe the coded information recorded against a patient (JOURNALS) and the demographic information about the patient (PATIENTS) are held in the same physical record. This means that, without needing to join the two tables which would be a less efficient and more costly operation, they are easily and efficiently retrievable together in the same query operations.
Conceptually this can be thought of as each JOURNAL record contains additional columns containing the details from the PATIENTS table about the patient corresponding to the JOURNAL record.
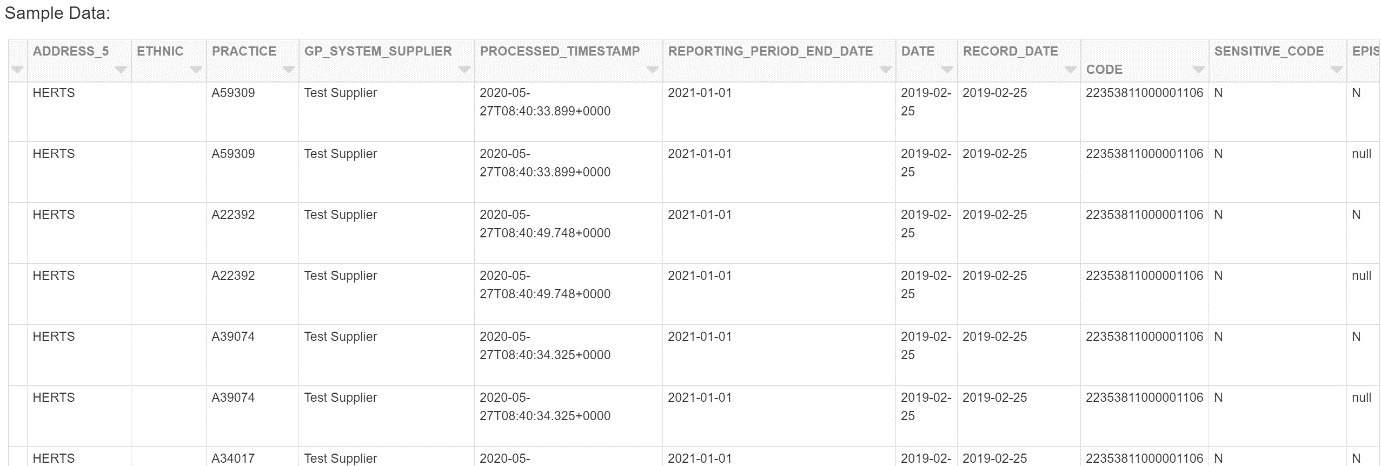
This diagram is showing the merged view that is provided within the eventual data asset for utilisation – the CODE column is the SNOMED CT code of the journal entry, ADDRESS_5 and ETHNIC are from the PATIENT table.
Current or historical data
The merged view, which forms the GDPPR data asset, will always contain the most up-to-date view of the data for example new records and the corresponding patient information will be appended to this view as they are extracted and processed. It is suggested that users utilise the available snapshots of the data, or create their own, to provide a stable dataset for analysis and to enable replication of results from previous analyses.
To view the most up-to-date version of a patients record users should utilise the REPORTING_PERIOD_END_DATE and JOURNAL_REPORTING_PERIOD_END_DATE fields. These fields contain the date that journal records were extracted from GP systems and can therefore be used to filter the data to only include the most recent extract date for each patient. By using the maximum JOURNAL_REPORTING_PERIOD_END_DATE for each patient users are able to filter out journals which may have been amended or deleted as these journals will have older dates.
Reference data
In its current state, the data asset can be aggregated by grouping on any of the current fields in the data for example patient level (NHS_NUMBER), practice level (PRACTICE) or supplier level (GP_SYSTEM_SUPPLIER). To aggregate by other possible areas of interest, such as Integrated Care Board (ICB) or Region, users will need to join reference data to the GDPPR data asset. This process will be different depending on whether users access the asset via a physical data extract via MESH, or the DAE.
Physical extract - reference data
Users with a physical extract of the GDPPR data asset can download reference data through the TRUD.
DAE reference data
Within the DAE, reference data is stored in the dss_corporate database. NHS England internal users can use the DSS report to understand what reference data is available, and how it should be used to filter the GDPPR data asset.
External users are advised to look at the Data Registers Service to understand what reference data is available, and how it should be used to filter the GDPPR data asset.
Reference tables which are thought to be particularly useful to the GDPPR data asset are listed in this table.
| Asset name | Description | Notes | Fields to join a= GDPR, b =reference data |
|---|---|---|---|
| ods_practice_v02 | Contains practice mapping information including practice names and the codes of the CCG or region they belong to |
To get data for open and active practices this table must be filtered using: DSS_RECORD_END_DATE is null CLOSE_DATE is null |
a.PRACTICE = b.CODE |
| gp_patient_list | Contains the number of patients registered at GP practices broken down by age and gender | For the correct GP patient list size, EXTRACT_DATE should be filtered to the first of whichever month GDPPR data was most recently extracted for example if data was last extracted on 2020-05-18 then EXTRACT DATE = 2020-05-01 | a.PRACTICE = b.PRACTICE_CODE |
| org_daily | Contains further mapping information | This table should be used in conjunction with ods_practice_v02 for mapping regions or CCGs
For the most recent information the table should be filtered using: ORG_CLOSE_DATE is null BUSINESS_END_DATE is null ORG_IS_CURRENT = 1 Mapping information for GP practices are available within this table but are not as frequently updated hence why ods_practice_v02 should be used in conjunction with org_daily. |
b.ORG_CODE = relevant field from ods_practice_v02 |
Analytical code
GDPPR subject matter experts have completed various analyses using the GDPPR and are sharing code to:
- prevent duplication of work
- allow peer review of code and methodology used in analysis
- increase consistency of methodology across users
- increase general knowledge sharing
This GitHub code repository contains various analytical code such as code to categorise various patient factors such as ethnicity and BMI. If users would like to suggest changes to the available code or add their own code to the repository then please submit a pull request all analytical code related to the GDPPR dataset is welcome.
Last edited: 4 September 2025 1:50 pm